ClassNotFoundException,...$MapClass not found
标签:大数据, hadoopidea工具调试
如果说idea或者eclipse之前在编写的map/reduce程序后直接通过run as的方式能够运行,但是突然某天运行后报错,报错信息却下Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class mac.cn.SecondSort.advanced.after.SecondSortRunner1$MapClass not found,这里分析下为何出现这个问题。
1.之前为何没有问题?
那么为何之前没有问题呢,下面的目录结构是没有问题的目录结构
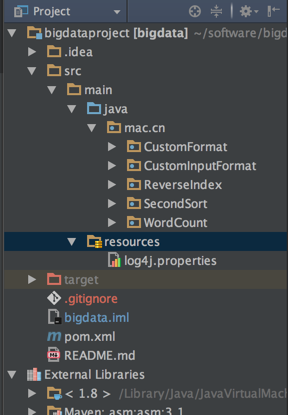
下面的目录结构是出现问题之后的目录结构:
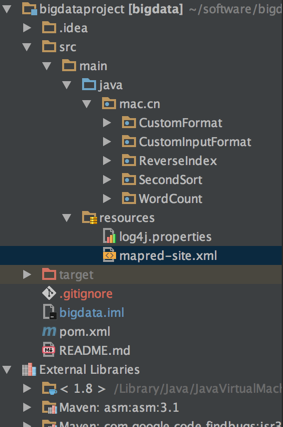
对比两张图片我们发现,在resources目录下多了一个文件,文件名称为mapred-site.xml文件,该文件是我直接从hadoop集群环境中拷贝过来的,那么该文件是做什么的?又有什么用呢?
2.mapred-site.xml文件内容:
这里我们在集群中配置的mapred-site.xml文件很简单,内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
也就是说文件中只有这没一行内容,再无其他。
3.原因分析
那么这一样内容有何作用呢?原来该property文件中的mapreduce.framework.name属性是用来指定mapreduce任务运行的方式,该属性该如何配置呢,通过查看mapred-default.xml我们发现该属性定义为:
<property>
<name>mapreduce.framework.name</name>
<value>local</value>
<description>The runtime framework for executing MapReduce jobs.
Can be one of local, classic or yarn.
</description>
</property>
也就是说属性mapreduce.framework.name有三个取值,分别是local,classic,yarn.
local本地模式,不会使用yarn集群来分配资源,直接在本地节点执行,在本地模式下执行的任务无法发挥集群的作用,而且执行的任务是不会在web ui中查看到的
classic是针对mapreduce1而言,为了兼容老版本的mapreuce框架而定
yarn集群管理模式,会通过YarnRunner与resourcemanager通信
所以上面在加入该文件之前,没有显示指定mapreduce.framework.name,因此默认为local本地模式,这样任务是不会提交到集群中,所以本地肯定有map,rducer及runner的相关类文件。 当加入该文件后,mapreduce.framework.name由默认的local本地模式改为yarn,运行后,hadoop框架需要将job提交到集群中,而集群中是不存在相关的map,reducer类的。
4.解决方案
如果显示的将mapreduce.framework.name改为了yarn,idea则可通过下面步骤来解决(eclipse可以变通修改):
file->project structure->artifacts->+->jar->from modules with dependiences
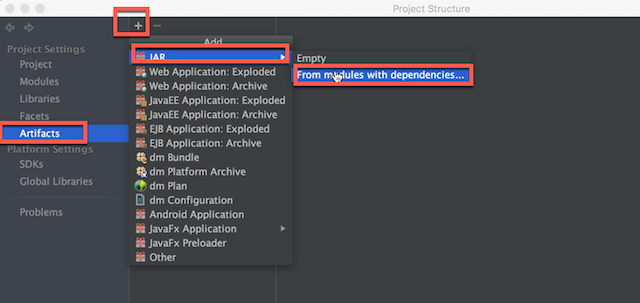
设置主类
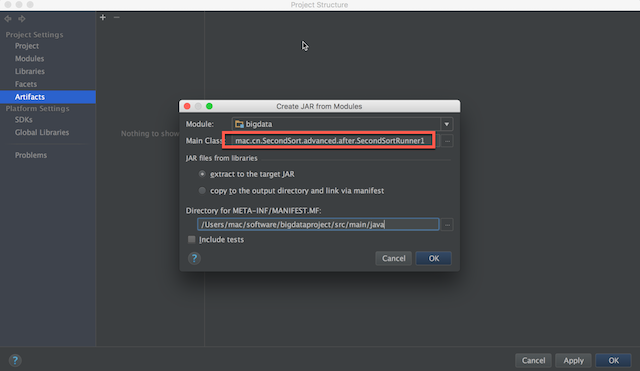
勾选build on make
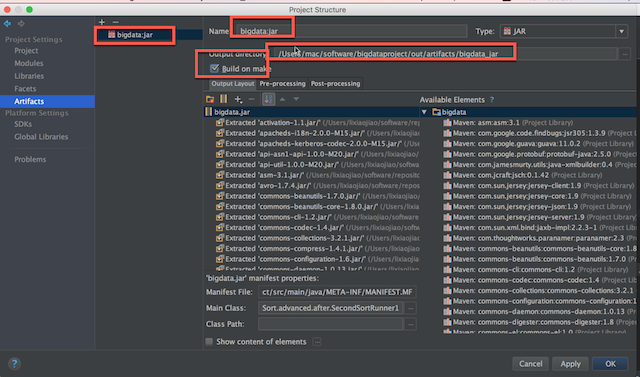
最后在java代码中添加下面代码来指定jar的路径
job.setJar("/Users/mac/software/bigdataproject/out/artifacts/bigdata_jar/bigdata.jar");
5.最后运行runner或者driver启动类,不会报错。
原创文章,转载请注明出处!
本文链接:https://codetosurvive1.github.io/posts/hadoop-class_not_found_idea.html